Okay, chcel som si v metagoofil prezrieť moju stránku a či obsahuje nejaké pdf súbory. No, ale, milý metagoofil nefičí a má bug? Tak, čo teraz? Klientka ma tlačí do parsovania jej webu a sú to tisíce stránok.
Ako etický heker musím rýchlo pohnúť rozumom a idem na to takto: https://hrubos.tech/blogy/content/images/20260619192318-Screenshot_2026-06-19_17_23_02.png
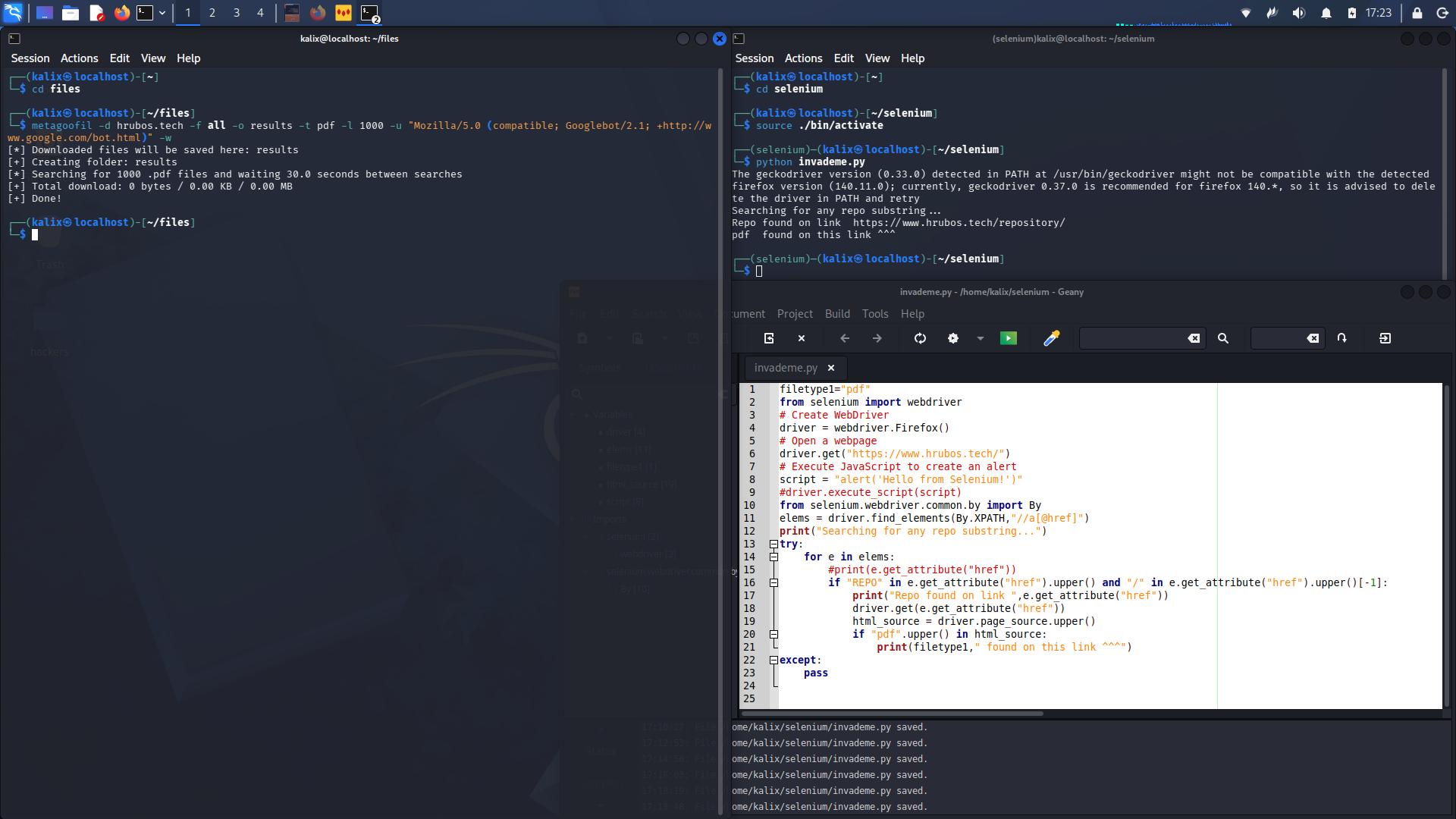
filetype1="pdf"
from selenium import webdriver
# Create WebDriver
driver = webdriver.Firefox()
# Open a webpage
driver.get("https://www.hrubos.tech/")
# Execute JavaScript to create an alert
script = "alert('Hello from Selenium!')"
#driver.execute_script(script)
from selenium.webdriver.common.by import By
elems = driver.find_elements(By.XPATH,"//a[@href]")
print("Searching for any repo substring...")
try:
for e in elems:
#print(e.get_attribute("href"))
if "REPO" in e.get_attribute("href").upper() and "/" in e.get_attribute("href").upper()[-1]:
print("Repo found on link ",e.get_attribute("href"))
driver.get(e.get_attribute("href"))
html_source = driver.page_source.upper()
if "pdf".upper() in html_source:
print(filetype1," found on this link ^^^")
except:
pass
A inde Silvo Stalone vraví vo filme Specialista: Nemúžu ťe zabít! Seš specialista! Bjež, utíkej...
Comments “Okay si etický heker a metagoofil nefičí! Čo spravíš? Napíšeš rýchlo vlastný? Samoška, že hej, a to takto:”