Uvažujme dnes ďalej, čo spraví regresia SVR v našom predošlom modeli: https://hrubos.tech/blogy/2025/12/co-tak-vlastny-ai-bot-ktory-inteligentne-odpoveda-v-projekte-commie A mohli by sme túto regresnú rovnú čiaru vylepšovať? Ukážme si algoritmus SVR, naozaj vytvára v modeli vizuálne rovnú čiaru:
Vlastne v modeli ^^^ SVR mašín lérningu dostávame rovnú čiaru, akoby sme združovali len kľúče poľa a spätnou väzbou hľadali daný podkľúčik, čo nám vytvorilo rovnú čiarku. Pre toto som sa rozhodol použiť na skúšku algo ká najbližších a ten nám nevytvára rovnú čiaru, ale v modeli vyberie tzv klástre alebo inak rovnaké podoblasti a toto už vyzerá pre tréning aj predikciu lepšie ako na titulnom obrázku:
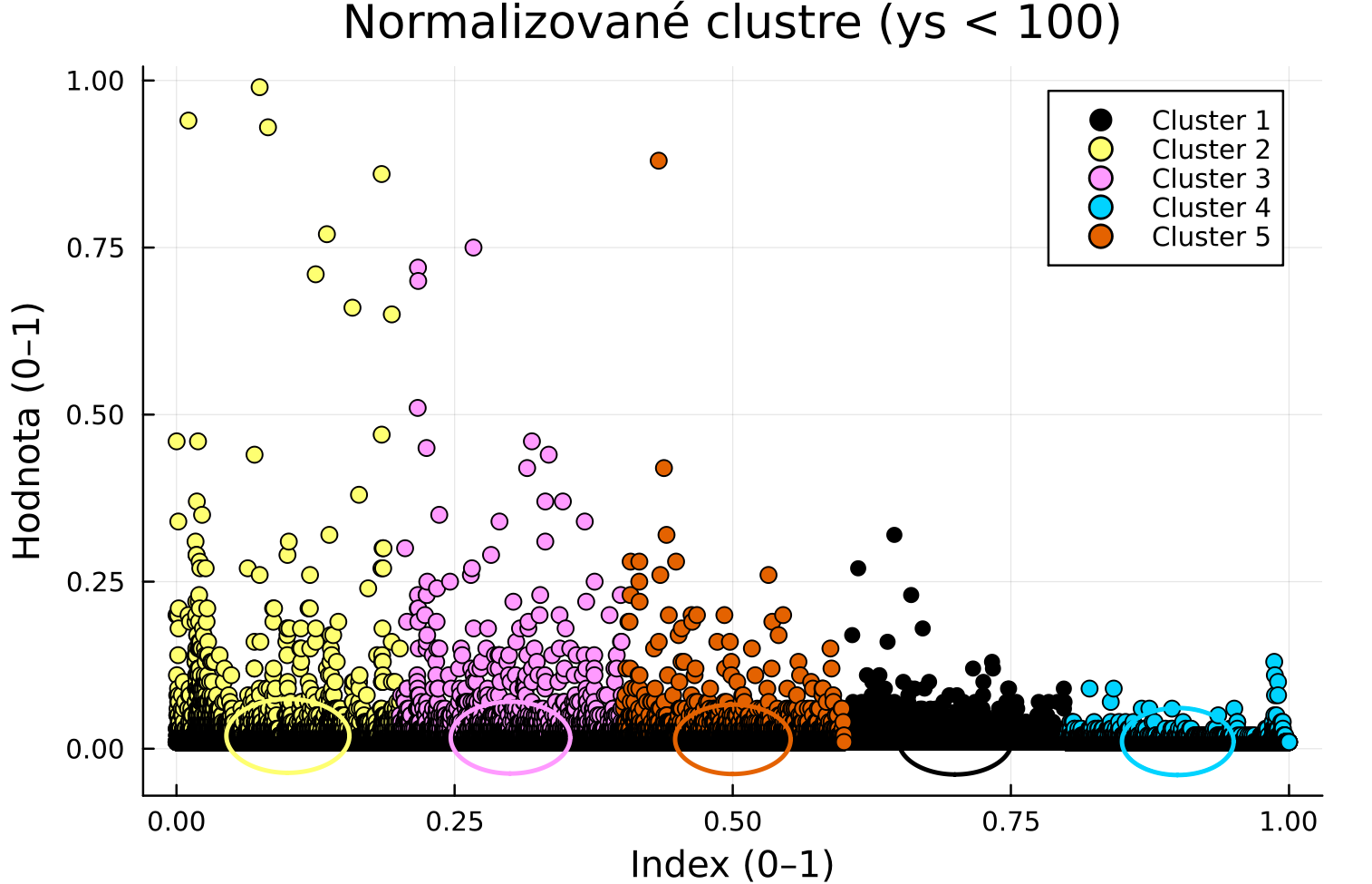
Následne ^^^ by sme mohli orezať tzv core layer alebo alpha/gamma layer, ktorú nám vďaka SVR vidno na K-NEAREST obraze s clusteringom ^^^
Julia lang src pre clusters:
using Pkg
Pkg.add("Plots")
Pkg.add("JSON")
Pkg.add("Clustering")
Pkg.add("Statistics")
using JSON
using Plots
using Clustering
using Statistics
# Načítanie JSON súboru
data = JSON.parsefile("model.json")
# Zozbierame všetky y do jedného zoznamu
ys_all = Float64[]
for (key, subdict) in data
ys = collect(values(subdict))
if maximum(ys) < 100
append!(ys_all, ys)
end
end
# Pripravíme normalizované dáta
N = length(ys_all)
xs_raw = collect(1:N) # pôvodné indexy
ys_raw = ys_all # pôvodné hodnoty
# NORMALIZÁCIA 0–1
xs = (xs_raw .- minimum(xs_raw)) ./ (maximum(xs_raw) - minimum(xs_raw))
ys = ys_raw ./ 100.0 # keďže max < 100, toto je validné
# Vytvoríme dataset pre KMeans (2×N matica)
X = hcat(xs, ys)'
k = 5
# Clustering
res = kmeans(X, k)
# Farby
palette = distinguishable_colors(k)
# Vizualizácia
plt = scatter(title = "Normalizované clustre (ys < 100)",
xlabel = "Index (0–1)",
ylabel = "Hodnota (0–1)",
legend = :topright)
for c in 1:k
idx = findall(res.assignments .== c)
xs_c = xs[idx]
ys_c = ys[idx]
# Scatter bodov clustra
scatter!(plt, xs_c, ys_c; label="Cluster $c", color=palette[c])
# Centroid
cx, cy = res.centers[:, c]
# Polomer clustra (priemerná vzdialenosť od centroidu)
dist = [sqrt((x-cx)^2 + (y-cy)^2) for (x,y) in zip(xs_c, ys_c)]
r = mean(dist)
# Kreslíme kruh
θ = range(0, 2π, length=200)
circle_x = cx .+ r .* cos.(θ)
circle_y = cy .+ r .* sin.(θ)
plot!(plt, circle_x, circle_y; lw=2, color=palette[c], label=false)
end
display(plt)
if !Base.isinteractive()
println("Press enter to quit:")
readline()
end
Ták a toto by bolo k dnešnému učeniu modelu a jeho vylepšovaniu, aby náš četbot lepšie videl na slovnú zásobu. Takto ho budeme učiť a vylepšovať chápať, čo mu hovoríme ;)
Comments “Ok, dnes o5 vylepšujme našu SVR ML analýzu a skúsme použiť na model algo zvaný ká-najbližších, vďaka nemu četbot uvidí nie rovnú čiaru, ale zhluky podobných slov. Nakreslím:”